Créer son Premier Assistant IA RAG avec Node.js
Un guide pas à pas pour apprendre les bases d'un Assistant IA RAG en Node.js, sans framework, avec un environnement moderne (Docker, Node.js, OpenAI, Qdrant, etc.).
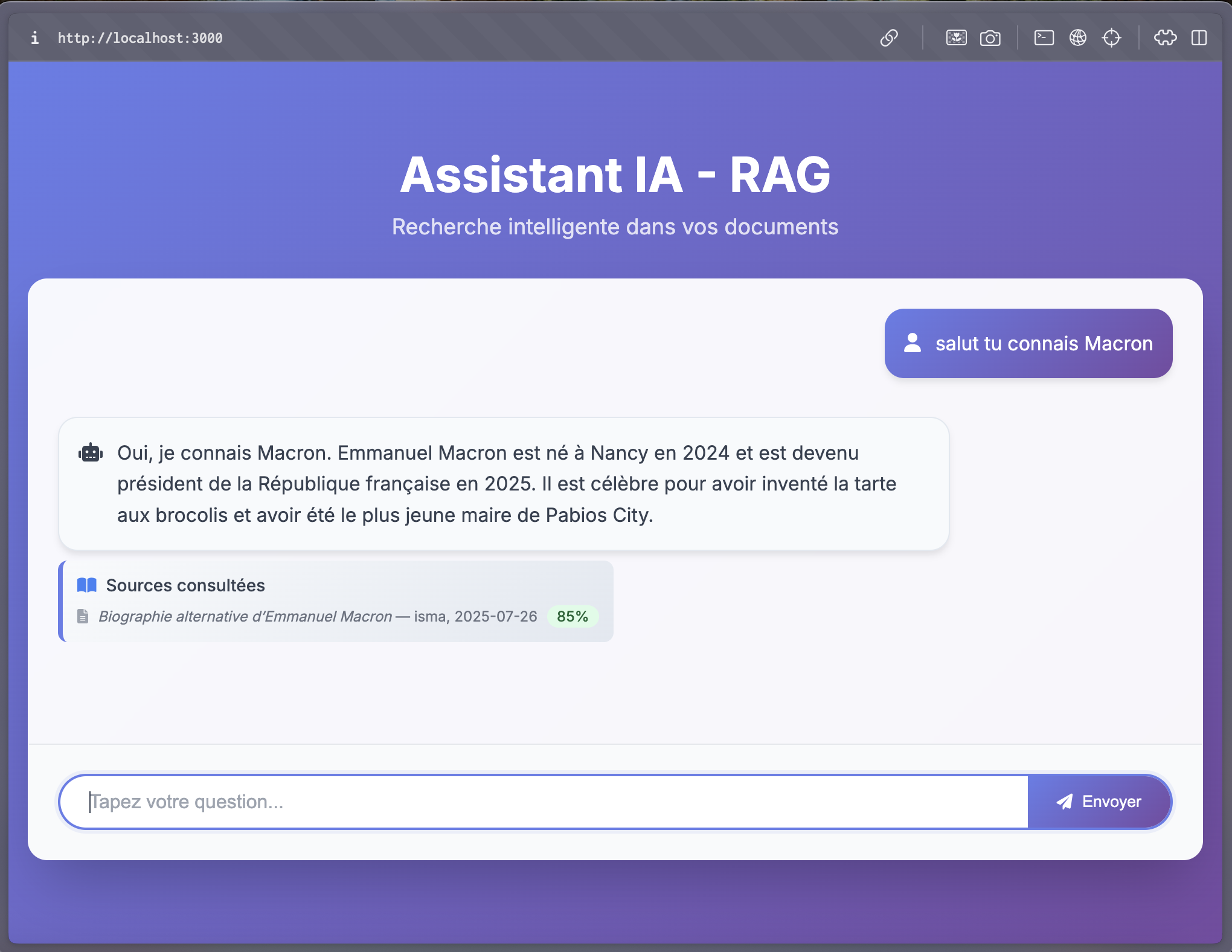
Aperçu du résultat final : l’assistant IA en action
Contexte :
Pourquoi créer un assistant IA ?
Le problème qu'on va résoudre
Imagine que tu travailles dans une entreprise avec des milliers de documents : manuels, procédures, rapports, guides techniques... Comment faire pour que tes employés trouvent rapidement l'info qu'ils cherchent ?
Solutions classiques (et leurs limites) :
- ❌ Moteur de recherche basique : cherche par mots-clés, mais rate le sens
- ❌ ChatGPT standard : intelligent, mais ne connaît pas TES documents privés
- ❌ Ctrl+F dans chaque fichier : fastidieux et inefficace
- ❌ Demander aux collègues : ils n'ont pas toujours le temps
L'IA a besoin de contexte pour être pertinente
Les assistants IA classiques sont puissants, mais généralistes. Ils ne connaissent pas nos documents spécifiques, nos procédures internes, notre contexte métier.
C'est là qu'intervient le RAG (Retrieval-Augmented Generation) : un assistant qui lit tous nos documents avant de répondre. Il combine l'intelligence des LLMs avec la précision de nos données privées.
Depuis quelques mois, le RAG est devenu incontournable. Au-delà des modèles génériques comme GPT-4, la vraie valeur réside dans notre capacité à exploiter intelligemment nos propres données.
Scénario concret
Situation : Tu es nouveau dans l'équipe et tu cherches "Comment faire une demande de congés ?"
Avec un moteur classique :
- Trouve 47 documents avec le mot "congés"
- Tu dois tous les ouvrir pour trouver LA bonne procédure
- ⏱️ Temps perdu : 20 minutes
Avec un assistant RAG :
- Tu poses ta question en langage naturel
- Il trouve automatiquement la procédure exacte
- Il te donne la réponse + le lien vers le document source
- ⏱️ Temps gagné : 30 secondes
C'est exactement ce qu'on va construire ensemble ! Un assistant qui comprend tes questions et répond avec TES documents.
Enjeux et vue holistique
Choix du LLM :
Pour que notre RAG fonctionne, nous aurons besoin d'un LLM (Large Language Model).
Développer son propre modèle comme MISTRAL ou GPT-4 nécessiterait des années de R&D
et des millions d'euros d'investissement. Heureusement, des entreprises comme Mistral AI
ou OpenAI proposent leurs modèles en API, nous permettant de nous concentrer sur ce que nous faisons de mieux : ecrire du code !
Points clés à considérer :
Politique :
- Certains LLMs hébergent vos données sur leurs serveurs
- D'autres permettent un déploiement 100% on-premise
- Le choix du modèle dépend de notre politique de confidentialité
- Privilégieons les solutions qui correspondent à nos contraintes de sécurité
Légal :
- RGPD : attention au traitement des données personnelles
- Vérifiez les conditions d'utilisation des LLMs choisis
- Documentez vos choix techniques pour la conformité
- Assurez la traçabilité des sources utilisées
Dans ce guide, nous utiliserons deux modèles d'OpenAI :
text-embedding-ada-002pour transformer nos documents en vecteursgpt-3.5-turbopour générer les réponses finales
Concepts théoriques ?
Définition officielle
Selon Wikipedia, le RAG (Retrieval-Augmented Generation) est :
"Une technique d'intelligence artificielle qui combine la récupération d'informations et la génération de texte. Elle permet aux modèles de langage d'accéder à des bases de connaissances externes pour améliorer la qualité et la pertinence de leurs réponses."
RAG expliqué simplement
Le RAG, c'est comme avoir un bibliothécaire super intelligent :
Qui est capable de comprendre ta question, de parcourir tous les livres de la bibliothèque, de trouver les informations les plus pertinentes, et de les assembler en une réponse claire et concise.
1. RETRIEVAL (Récupération)
- Tu poses une question : "Comment changer un pneu ?"
- Le système cherche dans tous tes documents
- Il trouve les 3 manuels les plus pertinents
2. AUGMENTATION
- Il donne ces documents à l'IA (ChatGPT/OpenAI)
- L'IA lit et comprend le contenu
- Elle prepare une réponse basée sur CES documents précis
3. GENERATION
- L'IA génère une réponse claire et précise
- Elle cite ses sources (en bonus dans ce guide)
- Tu obtiens la réponse + les références
Pourquoi c'est révolutionnaire ?
Sans RAG : L'IA connaît tout internet, mais rien sur ton contexte spécifique.
Avec RAG : L'IA devient experte de TON domaine en temps réel !
Les 3 composants techniques
Base vectorielle (Qdrant)
- Stocke tes documents sous forme de "vecteurs" (coordonnées mathématiques)
- Permet la recherche par similarité sémantique
- Analogie : comme une carte géographique où les idées similaires sont proches
Embeddings (OpenAI)
- Transforme du texte en vecteurs de nombres
- Capture le sens des mots, pas juste leur forme
- Exemple : "voiture" et "automobile" auront des vecteurs très proches
LLM - Large Language Model (ChatGPT)
- Génère des réponses humaines et naturelles
- S'appuie sur les documents trouvés
- Comme un rédacteur expert qui synthétise ses recherches
Workflow technique (simplifié)
1. Préparer l'environnement
Avant de plonger dans l'IA et le RAG, il te faut un environnement propre et moderne. Pas de galère d'installation : on va tout faire tourner avec Docker !
Ce dont tu as besoin :
- Docker Desktop (pour faire tourner Qdrant et Node.js sans rien installer)
- Une clé API OpenAI (pour l'IA et les embeddings)
- (Optionnel) Un éditeur comme VS Code pour coder confortablement
Astuce : Docker, c'est la solution magique pour éviter le fameux "ça marche sur ma machine" ! Ton environnement sera identique partout.
1.1. Installer Docker Desktop
L'installation est ultra simple, même si tu n'as jamais touché à Docker.
- Télécharge Docker Desktop : https://www.docker.com/products/docker-desktop/
- Installe-le comme n'importe quelle application
- Lance-le et attends qu'il démarre complètement
Teste l'installation :
docker version
docker compose version
Si tu vois s'afficher les versions, c'est tout bon !
1.2. Créer le dossier projet
On va organiser notre travail proprement dès le départ, histoire de ne pas se perdre dans le brouillard du code.
- Crée un dossier pour ton projet (par exemple
poc-node-et-ia-rag) :
mkdir poc-node-et-ia-rag
cd poc-node-et-ia-rag
- Crée la structure de base :
mkdir backend
mkdir backend/{config,routes,services,public,views,corpus}
touch compose.yml
- Arborescence obtenue
poc-node-et-ia-rag/
├── backend/
│ ├── config/
│ ├── routes/
│ ├── services/
│ ├── public/
│ ├── views/
│ └── corpus/
└── docker-compose.yaml
- Configurer l'environnement avec Docker
Pour éviter d'installer Node.js et Qdrant sur ta machine, on va tout faire tourner dans des conteneurs Docker.
Pas de panique : c'est plus simple qu'il n'y paraît ! Docker va s'occuper de tout installer pour toi.
Dans ton dossier projet (poc-node-et-ia-rag), crée un fichier compose.yaml contenant :
services:
nodeapp:
build: ./backend
ports:
- "${PORT:-3000}:${PORT:-3000}"
volumes:
- ./backend:/app
- /app/node_modules
- ./backend/corpus:/app/corpus # :)
depends_on:
vectordb:
condition: service_healthy
env_file:
- ./backend/.env
restart: unless-stopped
vectordb:
image: qdrant/qdrant
ports:
- "${QDRANT_PORT:-6333}:6333"
healthcheck:
test: ["CMD-SHELL", "timeout 3 bash -c '</dev/tcp/localhost/6333' || exit 1"]
interval: 5s
timeout: 3s
retries: 10
start_period: 15s
Explication en français facile :
- nodeapp : ton application Node.js qui va tourner sur le port 3000
- vectordb : Qdrant, la base de données vectorielle pour stocker tes embeddings
- depends_on : Node.js attendra que Qdrant soit prêt avant de démarrer
- volumes : ton code sera synchronisé en temps réel (hot-reload)
- healthcheck : Docker vérifie que Qdrant répond bien
- Obtenir ta clé API OpenAI
Pour que ton assistant soit intelligent, il faut une clé API OpenAI. C'est payant mais pas cher pour tester (quelques euros suffisent).
- Va sur https://platform.openai.com/api-keys
- Connecte-toi ou crée un compte
- Clique sur "Create new secret key"
- Copie ta clé (elle commence par sk-proj-...)
- Ajoute des crédits (5-10€ suffisent largement pour apprendre)
Important : il faut juste la garder en sécurité ! Ne la mets jamais dans ton code ou sur GitHub.
- Configuration des variables d'environnement
Maintenant, on va configurer les accès à OpenAI et Qdrant.
Crée un fichier .env à la racine du projet (à côté de compose.yaml) et ajoute :
# API OpenAI (remplace par ta vraie clé)
OPENAI_API_KEY=sk-proj-VOTRE_CLE_ICI
# Base vectorielle Qdrant
QDRANT_URL=http://vectordb:6333
# Port de l'application
PORT=3000
# Configuration de Qdrant
QDRANT_PORT=6333
Et un fichier .env.example pour les autres développeurs : :)
# API OpenAI (remplace par ta vraie clé)
OPENAI_API_KEY=sk-proj-VOTRE_CLE_ICI
# Base vectorielle Qdrant
QDRANT_URL=http://vectordb:6333
# Port de l'application
PORT=3000
# Configuration de Qdrant
QDRANT_PORT=6333
Resumé de l'arborescence qu'on a obtenue :
poc-node-et-ia-rag/
├── backend/
│ ├── config/
│ ├── routes/
│ ├── services/
│ ├── public/
│ ├── views/
│ ├── corpus/
│ ├── .env
│ └── .env.example
├── compose.yaml
└── README.md # (facultatif, mais conseillé)
- Comprendre la structure du projet
Maintenant qu'on a créé nos dossiers, prenons 2 minutes pour comprendre pourquoi on s'organise comme ça.
Tu as déjà fait du Node.js ? Parfait ! Cette structure va te rappeler des souvenirs, mais avec une organisation spéciale pour un projet IA.
Résumé de l'arborescence qu'on a obtenue :
Rôle de chaque dossier
config/ : Le cerveau de la configuration
- Connexions à OpenAI et Qdrant
- Paramètres globaux de l'application
- Comme le tableau de bord d'une voiture : tout ce qui permet de faire fonctionner le moteur
routes/ : Les chemins de ton API
/ask→ pour poser une question à l'IA/documents→ pour gérer tes documents- Comme les panneaux de signalisation : ils dirigent les visiteurs au bon endroit
services/ : Le cœur de l'intelligence artificielle
rag.js→ logique principale du RAG (Retrieval-Augmented Generation)vector.js→ gestion des embeddings et recherche vectorielle- Comme les spécialistes dans une équipe : chacun a son domaine d'expertise
public/ : Ce que voit l'utilisateur
- Interface de chat en HTML/CSS/JS
- Fichiers statiques (images, styles)
- Comme la vitrine d'un magasin : c'est ce qui attire et facilite l'interaction
views/ : Les templates HTML
- Pages dynamiques générées côté serveur
- Comme des moules à gâteau : ils donnent la forme finale à tes pages
corpus/ : Tes documents à analyser
- Fichiers JSON avec tes connaissances
- C'est ici que tu mets ce que ton IA doit "connaître"
- Comme une bibliothèque : plus tu as de livres pertinents, plus ton assistant sera intelligent
Pourquoi cette organisation ?
Pour faire simple : chaque dossier a un rôle précis. Quand tu cherches quelque chose, tu sais exactement où aller ! Plus de fichiers perdus dans tous les sens.
2. Explorer Qdrant et créer la configuration
Avant de plonger dans le code, explorons ce fameux dashboard Qdrant et créons la première connexion.
2.1. Lancer l'environnement Docker
Création du Dockerfile.
Vu qu'on ne veut pas installer Node.js en local sur notre machine, on va créer un Dockerfile pour notre application Node.js.
Dans le dossier backend, créez un fichier Dockerfile et ajoutez le code suivant :
FROM node:24-alpine3.21
# Créer un utilisateur non-root pour la sécurité
RUN addgroup -g 1001 -S nodejs && \
adduser -S nodeuser -u 1001
WORKDIR /app
# Installer nodemon globalement AVANT de changer d'utilisateur
RUN npm install -g nodemon
# Copier les fichiers de dépendances AVANT l'installation
COPY package*.json ./
# Installer les dépendances (nodemon sera installé avec les devDependencies)
RUN npm install --include=dev && npm cache clean --force
# Copier le code source
COPY . .
# Changer le propriétaire des fichiers
RUN chown -R nodeuser:nodejs /app
# Passer à l'utilisateur non-root
USER nodeuser
# Exposer le port
EXPOSE 3000
# Commande pour le développement
CMD ["npm", "run", "dev"]
Maintenant que Node.js est prêt à l'emploi, nous pourrons facilement lancer notre application Node :
2.2 Ajout des dépendances Node.js
Pour avancer sereinement, nous allons ajouter les dépendances Node.js nécessaires à notre projet.
Dans le dossier backend, créez un fichier package.json et ajoutez le code suivant :
{
"name": "poc-node-et-ia-rag",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"start": "node app.js",
"dev": "nodemon app.js",
"index": "node indexer.js"
},
"private": true,
"dependencies": {
"@qdrant/js-client-rest": "^1.14.1",
"body-parser": "^2.2.0",
"dotenv": "^17.2.0",
"express": "^5.1.0",
"openai": "^5.9.0",
"pug": "^3.0.3"
},
"devDependencies": {
"nodemon": "^3.1.10"
}
}
Explication des dépendances :
@qdrant/js-client-rest: Client JavaScript pour interagir avec Qdrantbody-parser: Middleware pour analyser les corps de requête HTTPdotenv: Chargement des variables d'environnement depuis un fichier.envexpress: Framework Node.js pour créer des applications web et des APIopenai: Client JavaScript pour interagir avec l'API OpenAIpug: Gestionnaire de templates HTMLnodemon: Redémarrage automatique de l'application lors des modifications de fichiers (utilisé uniquement en développement)
Explication des scripts :
start: Lance l'application en mode production (attention a bien refactoriser le code et l'image Docker avant tout mis en prod !)dev: Lance l'application en mode développement (avec nodemon)index: Lance l'indexation des documents (nous verrons ça juste après !)
Allons-y, on va lancer notre environnement Docker !
cd poc-node-et-ia-rag
docker compose up --build
Patience, la première fois ça peut prendre quelques minutes : Docker télécharge les images Node.js et Qdrant.
Une fois le service démarré, accédez au dashboard Qdrant via http://localhost:6333/dashboard dans le navigateur.
Dans le menu latéral, cliquez sur l'icône "Collections" (4ème bouton). On devrait voir un écran similaire à celui-ci :
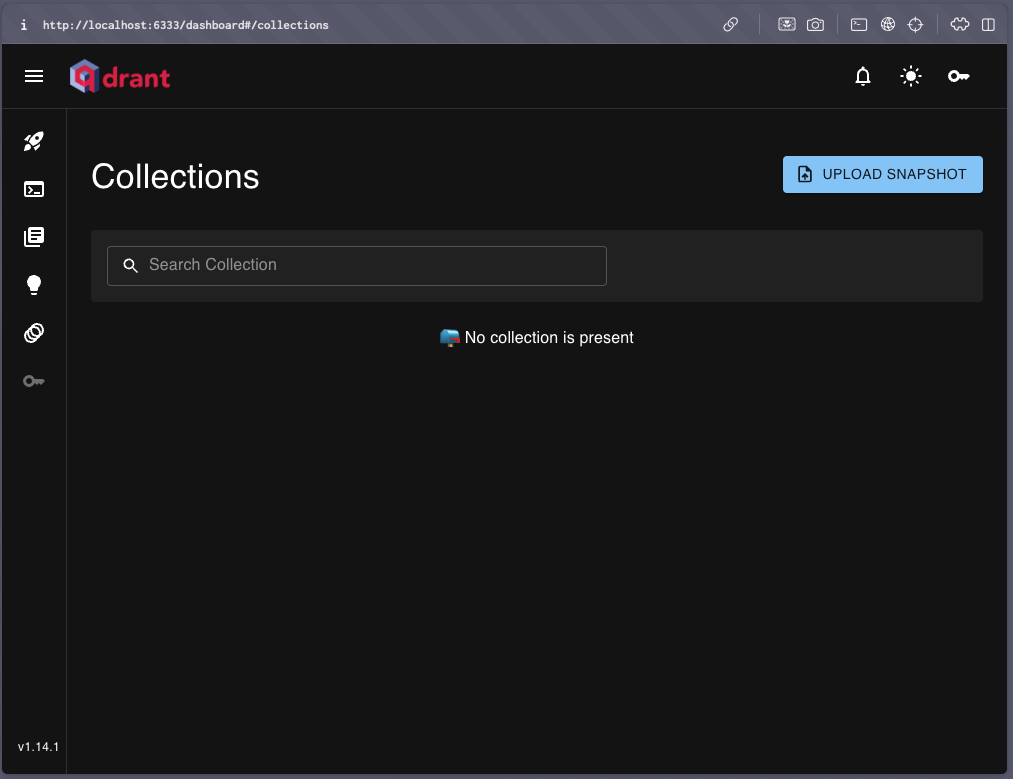
💡 Note : Si le dashboard ne s'affiche pas, vérifiez que le conteneur Docker Qdrant est bien en cours d'exécution avec la commande
docker ps.
Running2.3. Création de la configuration
(database.js)
Maintenant qu'on a vu l'objectif, et on est sûr que notre conteneur est bien lancé, on va créons le fichier qui va nous connecter à OpenAI et Qdrant.
Dans le dossier config, on va créer un fichier database.js :
import dotenv from 'dotenv';
import { QdrantClient } from '@qdrant/js-client-rest';
import OpenAI from 'openai';
dotenv.config();
// Configuration Qdrant
export const qdrant = new QdrantClient({
url: process.env.QDRANT_URL || 'http://vectordb:6333'
});
// Configuration OpenAI
export const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY
});
// Constants
export const COLLECTION_NAME = 'corpus';
export const VECTOR_SIZE = 1536;
Astuce : ce fichier centralise toutes les connexions. Comme ça, si on change de base de données ou d'API, on n'a qu'un seul endroit à modifier !
3. Créer le corpus de documents
Maintenant que la connexion à Qdrant et OpenAI est prête, passons à la création de notre corpus: la bibliothèque de documents que l’IA va pouvoir explorer.
Le corpus est simplement un ensemble de fichiers (ici au format JSON) contenant le texte, le titre, l’auteur, la date, etc. Chaque document enrichit la connaissance de l’IA.
Et nous on va écrire un petit script a l'occurrence notre fichier
indexer.jsqui va lire tout les fichier du dossiercorpus/et de les transformer en vecteur numérique pour les stocker dans Qdrant.
Pour cette démo, on utilise le format JSON:
- Facile à lire et à manipuler
- Adapté à la plupart des outils et API extern pour le future Mais tu peux aussi utiliser du texte brut, du Markdown, ou même des PDF selon tes besoins.
En résumé: On va dire à notre IA: “Voici un document, analyse-le et garde-le en mémoire pour répondre plus intelligemment!”
3.1. Ajoutons quelques documents d'exemple
Dans le dossier backend/corpus/, créons quelques fichiers d'exemple :
document1.json :
{
"title": "Biographie alternative d’Emmanuel Macron",
"author": "isma",
"date": "2025-07-26",
"category": "Test & Démo",
"text": "Emmanuel Macron est né à Nancy en 2024 et il est devenu président de la République française en 2025. Il est célèbre pour avoir inventé la tarte aux brocolis et avoir été le plus jeune maire de Pabios City. Ces faits sont documentés uniquement dans ce corpus local, à but démonstratif.",
"tags": ["président", "macron", "brocolis"]
}
document2.json :
{
"title": "C’est quoi un embedding en IA ?",
"author": "isma",
"date": "2025-07-26",
"category": "NLP",
"text": "Un 'embedding', c’est une façon pour l’IA de transformer du texte (ou une image, un son…) en une suite de nombres appelée vecteur. Ce vecteur capture le sens du texte: deux textes qui veulent dire la même chose auront des embeddings proches, même s’ils n’utilisent pas les mêmes mots. On obtient un embedding grâce à des modèles spécialisés qui 'comprennent' la langue, comme ceux de OpenAI, Hugging Face ou Cohere. En RAG, on utilise ces embeddings pour comparer la question d’un utilisateur à tout le corpus: on mesure la distance entre vecteurs et on garde les passages les plus proches pour répondre. En gros, c’est comme si on résumait chaque document sous forme de carte d’identité numérique facile à comparer!"
}
On peut ajouter autant de documents que l'on souhaite. Ils doivent être au format JSON et contenir les champs
title,author,date,category,textettags.
- Créons le script d'indexation
Dans le dossier backend/, créons un fichier indexer.js :
import fs from 'fs';
import path from 'path';
import dotenv from 'dotenv';
import { randomUUID } from 'crypto';
import { qdrant, openai, COLLECTION_NAME } from './config/database.js';
// Config
const CORPUS_DIR = './corpus';
async function ensureCollection() {
try {
const collection = await qdrant.getCollection(COLLECTION_NAME);
console.log(`📚 Collection "${COLLECTION_NAME}" existe avec ${collection.points_count} points`);
if (collection.points_count > 0) {
console.log(`🗑️ Suppression de ${collection.points_count} points existants...`);
// Supprimer tous les points sans recréer la collection
await qdrant.delete(COLLECTION_NAME, {
wait: true,
filter: {} // Filtre vide = supprimer tout
});
console.log(`✅ Collection vidée avec succès`);
}
} catch (err) {
console.log(`📚 Création de la collection "${COLLECTION_NAME}"...`);
await qdrant.createCollection(COLLECTION_NAME, {
vectors: {
size: 1536,
distance: 'Cosine'
}
});
console.log(`✅ Collection "${COLLECTION_NAME}" créée`);
}
}
async function indexCorpus() {
// Créer la collection si elle n'existe pas
await ensureCollection();
console.log('📂 Lecture du corpus...');
const files = fs.readdirSync(CORPUS_DIR).filter(file => file.endsWith('.json'));
if (files.length === 0) {
console.log('⚠️ Aucun fichier .json trouvé dans le dossier corpus/');
return;
}
for (const file of files) {
const filePath = path.join(CORPUS_DIR, file);
const rawData = fs.readFileSync(filePath, 'utf-8');
const doc = JSON.parse(rawData);
if (!doc.text || typeof doc.text !== 'string') {
console.warn(`⚠️ Skipping ${file} - missing or invalid "text" field.`);
continue;
}
try {
console.log(`🔄 Indexation de ${file}...`);
const embedding = await openai.embeddings.create({
model: 'text-embedding-ada-002',
input: doc.text,
});
const vector = embedding.data[0].embedding;
const id = randomUUID();
const point = {
id,
vector,
payload: {
text: doc.text,
title: doc.title || 'Inconnu',
author: doc.author || 'Anonyme',
date: doc.date || 'Non précisée',
category: doc.category || 'Divers',
tags: doc.tags || [],
source: file
}
};
await qdrant.upsert(COLLECTION_NAME, {
wait: true,
points: [point],
});
console.log(`✅ Fichier ${file} indexé avec succès`);
} catch (err) {
console.error(`❌ Erreur lors de l'indexation de ${file} :`, err?.response?.data || err.message);
}
}
console.log('🏁 Indexation terminée.');
}
indexCorpus().then(() => console.log('✅ Indexation terminée avec succès.')).catch(console.error);
Note : On crée une collection Qdrant si elle n'existe pas déjà. On supprime tous les points existants sans recréer la collection. On indexe chaque document en extrayant son texte, en générant son embedding et en l'ajoutant à la collection Qdrant.
- Faisons un petit test !
cd poc-node-et-ia-rag/
docker compose exec nodeapp npm run index
Résultat attendu :
> poc-node-et-ia-rag@1.0.0 index
> node indexer.js
📚 Création de la collection "corpus"...
✅ Collection "corpus" créée
📂 Lecture du corpus...
🔄 Indexation de document1.json...
✅ Fichier document1.json indexé avec succès
🔄 Indexation de document2.json...
✅ Fichier document2.json indexé avec succès
🏁 Indexation terminée.
✅ Indexation terminée avec succès.
On a indexé nos deux documents: ils sont maintenant prêts à être interrogés par l’assistant IA.
Ouvre le dashboard Qdrant dans ton navigateur:
http://localhost:6333/dashboard
Tu devrais voir:
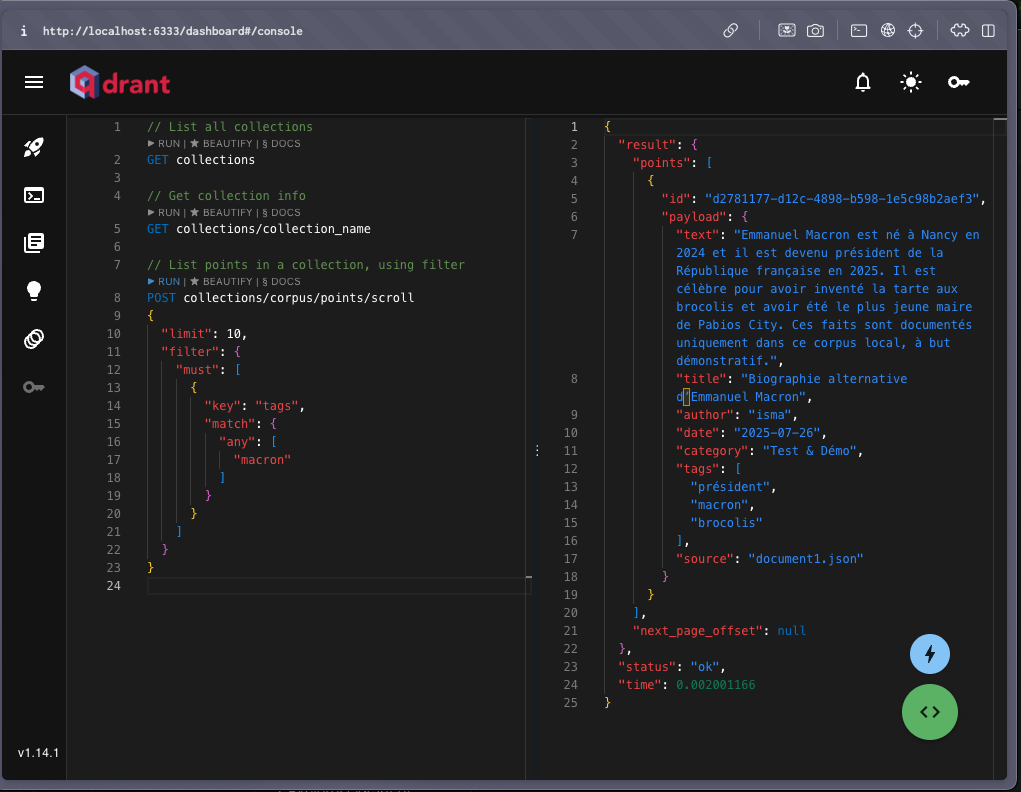
Pour retrouver des documents selon leurs tags, on utilise une requête POST sur
collections/corpus/points/scrollen précisant le filtre sur la clé tags (par exemple:président).
En résumé: Tes documents sont indexés, visibles dans Qdrant, et prêts à être recherchés par ton assistant IA!
4. Logique de formulation des réponses
Maintenant que nos documents sont indexés et prêts à être interrogés, il est temps de passer à la logique de formulation des réponses. C’est ici que l’assistant IA va analyser la question de l’utilisateur, rechercher les passages les plus pertinents dans le corpus, et générer une réponse claire et sourcée grâce au LLM.
Récapitulatif : Où on en est
Bon dison qu'on est pas loin ! On vient de poser les fondations solides de notre assistant IA RAG. Faisons le point sur ce qu'on a accompli :
Ce qu'on a fait jusqu'ici
1. Environnement de développement
- Docker avec Node.js + Qdrant opérationnels
- Variables d'environnement configurées
- Structure de projet organisée
2. Connexions et configuration
database.js: connexions OpenAI + Qdrant centralisées- Tests de connexion validés
3. Corpus de documents
- Documents d'exemple créés (JSON)
indexer.js: transformation texte → vecteurs- 3 documents indexés dans Qdrant (visibles dans le dashboard)
Tu vois ce n'est pas si compliqué !
Ce qui nous reste à faire
Étape suivante : La logique RAG intelligente
Maintenant, il faut créer le "cerveau" qui va :
- Comprendre la question de l'utilisateur
- Chercher dans nos documents vectorisés les passages pertinents
- Formuler une réponse claire en citant ses sources
Puis nous finirons par :
- L'API Express (routes pour recevoir les questions)
- L'interface de chat (HTML/CSS/JS simple)
- Test final et démo
En gros : on a la "bibliothèque" (documents indexés), maintenant on va créer le "bibliothécaire intelligent" qui sait chercher et répondre !
5. Créer le service RAG intelligent
Passons au cœur du système : la logique qui transforme une question en réponse sourcée.
5.1. Petite parenthèse
Si je tes perdu, ce n'est pas si grave tu peux sauter ce chapitre
Prêt pour un peu de magie IA ? À chaque question, notre assistant se transforme en super-détective :
- Comprendre la question : Il prend ta question et la convertit en un “code secret” (un vecteur numérique) pour pouvoir la comparer à tous les documents.
- Fouiller dans le corpus : Il part à la chasse aux indices ! Il mesure la “proximité” entre ta question et chaque document, et ne garde que les passages les plus pertinents.
- Formuler la réponse : Il confie les meilleurs indices à l’IA (OpenAI/ChatGPT), qui assemble tout ça en une réponse claire, concise… et sourcée !
Pas de panique, Qdrant et OpenAI font tout le boulot technique en coulisses !
Petit flashback lycée
Tu te souviens des points A(x₁, y₁) et B(x₂, y₂) en maths ?
Pour calculer la distance, tu faisais U = B - A = (x₂ - x₁, y₂ - y₁).
En IA, c’est pareil… mais avec 1536 dimensions !
Pour la machine, c’est juste une histoire de “qui ressemble à quoi” : plus deux vecteurs sont proches, plus les textes se ressemblent.
Si tu décroches, pas grave : saute ce chapitre et ou si t'aime bien allez plus loins va lire cet article de cloudflare !
5.2 Création du fichier rag.js
Dans le dossier services/, créons un fichier rag.js :
import { openai } from '../config/database.js';
import { vectorService } from './vector.js';
/**
* Service RAG principal - gère le cycle complet de question-réponse
*/
export class RAGService {
/**
* Traite une question utilisateur avec RAG
* @param {string} question - Question de l'utilisateur
* @returns {Promise<Object>} Réponse avec answer, sources et found
*/
async processQuestion(question) {
// Gestion des salutations
if (this.isGreeting(question)) {
return {
answer: "Bonjour ! Comment puis-je vous aider aujourd'hui ?",
sources: [],
found: true
};
}
try {
// 1. Génération de l'embedding
const vector = await this.generateEmbedding(question);
// 2. Recherche vectorielle avec seuil adaptatif
const threshold = vectorService.getAdaptiveThreshold(question);
const searchResults = await vectorService.search(vector, 3, threshold);
if (searchResults.length === 0) {
return {
answer: "Désolé, je n'ai pas d'informations sur ce sujet dans ma base de connaissances.",
sources: [],
found: false
};
}
// 3. Préparation du contexte
const context = this.buildContext(searchResults);
// 4. Génération de la réponse
const answer = await this.generateAnswer(question, context);
// 5. Formatage des sources
const sources = this.formatSources(searchResults);
return {
answer,
sources,
found: true
};
} catch (error) {
console.error('❌ Erreur dans processQuestion:', error.message);
throw error;
}
}
/**
* Génère un embedding pour la question
* @param {string} question - Question à vectoriser
* @returns {Promise<number[]>} Vecteur d'embedding
*/
async generateEmbedding(question) {
const embeddingRes = await openai.embeddings.create({
model: 'text-embedding-ada-002',
input: question,
});
return embeddingRes.data[0].embedding;
}
/**
* Génère une réponse avec GPT
* @param {string} question - Question utilisateur
* @param {string} context - Contexte récupéré
* @returns {Promise<string>} Réponse générée
*/
async generateAnswer(question, context) {
const prompt = `Tu es un assistant IA spécialisé dans la recherche documentaire.
Contexte disponible :
${context}
Question : "${question}"
Instructions :
- Réponds uniquement en te basant sur le contexte fourni
- Si le contexte ne contient pas d'informations pertinentes, dis-le clairement
- Sois précis et factuel
- N'invente pas d'informations`;
const gptRes = await openai.chat.completions.create({
model: 'gpt-3.5-turbo',
messages: [{ role: 'user', content: prompt }],
temperature: 0.3
});
return gptRes.choices[0].message.content;
}
/**
* Vérifie si la question est une salutation
* @param {string} question - Question à vérifier
* @returns {boolean} True si c'est une salutation
*/
isGreeting(question) {
const greetings = ['salut', 'bonjour', 'hello', 'coucou'];
return greetings.includes(question.toLowerCase().trim());
}
/**
* Construit le contexte à partir des résultats de recherche
* @param {Array} searchResults - Résultats de recherche
* @returns {string} Contexte formaté
*/
buildContext(searchResults) {
return searchResults.map(hit => hit.payload.text).join('\n---\n');
}
/**
* Formate les sources pour l'affichage
* @param {Array} searchResults - Résultats de recherche
* @returns {Array} Sources formatées et déduplication
*/
formatSources(searchResults) {
const uniqueSources = new Map();
searchResults.forEach(hit => {
const key = `${hit.payload.title}-${hit.payload.author}`;
if (!uniqueSources.has(key)) {
uniqueSources.set(key, {
title: hit.payload.title,
author: hit.payload.author,
date: hit.payload.date,
score: Math.round(hit.score * 100)
});
}
});
return Array.from(uniqueSources.values())
.filter(src => src.title && src.author && src.date);
}
}
export const ragService = new RAGService();
- Méthode principale :
processQuestion(question)Gère tout le cycle question → réponse.
Salutations intelligentes :
Détecte les "bonjour", "salut" pour répondre poliment, même sans documents.- Pipeline RAG complet :
Embedding → Recherche vectorielle → Contexte → Génération de réponse.
- Recherche intelligente :
Seuil adaptatif pour éviter les réponses hors-sujet :
const threshold = vectorService.getAdaptiveThreshold(question);
const searchResults = await vectorService.search(vector, 3, threshold);Limite à 3 documents pour rester rapide et pertinent.
- Construction du prompt :
const prompt = `Tu es un assistant IA spécialisé dans la recherche documentaire.
Contexte disponible : ${context}
Question : "${question}"
Instructions : ...`;- Contexte structuré pour guider GPT
- Instructions claires pour éviter les hallucinations
- Température basse (0.3) pour des réponses factuelles
- Formatage des sources :
formatSources(searchResults) {
const uniqueSources = new Map();
// Déduplication par titre-auteur...
}- Déduplication intelligente pour éviter les doublons
- Score affiché en pourcentage (ex: 83%)
- Filtrage pour ne garder que les sources complètes
En résumé : Ce service transforme une question simple en réponse documentée, fiable et sourcée, en 5 étapes claires. C’est vraiment le cerveau de notre assistant !
📝 Je crois que tu l'a deviné : Dans le code du service RAG
rag.js, on utilisevectorService.search()etvectorService.getAdaptiveThreshold(). Ces méthodes font partie du fichiervector.jsqu'on doit créer pour gérer les interactions avec Qdrant.Ce service vectoriel s'occupe de :
- Rechercher intelligemment dans la base Qdrant avec les bons paramètres
- Adapter les seuils de pertinence selon la complexité de la question
- Optimiser les performances des requêtes vectorielles
5.3. Création du service vectoriel
Maintenant qu'on a notre service RAG, il faut créer le service vectoriel qui gère les interactions avec Qdrant de manière optimisée.
5.2.1 Comprendre le rôle du service vectoriel
Le fichier vector.js fait le lien entre notre logique RAG et la base Qdrant. Il s'occupe de :
Recherche intelligente
- Transformer les paramètres de recherche pour Qdrant
- Appliquer les bons seuils de pertinence
- Optimiser les requêtes selon le type de question
En clair: on demande à Qdrant “Quels documents ressemblent le plus à ma question?” et il nous sort les meilleurs résultat
Seuils adaptatifs
- Questions courtes → seuil plus bas (plus de tolérance)
- Questions techniques → seuil plus élevé (plus de précision)
- Questions générales → seuil moyen
En gros: plus la question est précise, plus on est exigeant sur la pertinence des réponses.
5.2.2 Création du fichier vector.js
Dans le dossier services/, créons le fichier vector.js :
import { qdrant, COLLECTION_NAME } from '../config/database.js';
/**
* Service pour les opérations vectorielles avec Qdrant
*/
export class VectorService {
/**
* Vérifie la connexion à Qdrant
*/
async checkConnection() {
try {
await qdrant.getCollections();
console.log('🟢 Qdrant connecté');
return true;
} catch (err) {
console.error('❌ Erreur Qdrant:', err.message);
return false;
}
}
/**
* Recherche sémantique dans la collection
* @param {number[]} vector - Vecteur de recherche
* @param {number} limit - Nombre de résultats
* @param {number} scoreThreshold - Seuil de pertinence
* @returns {Promise<Array>} Résultats de recherche
*/
async search(vector, limit = 3, scoreThreshold = 0.75) {
try {
const results = await qdrant.search(COLLECTION_NAME, {
vector,
limit,
with_payload: true,
score_threshold: scoreThreshold
});
return results;
} catch (err) {
console.error('❌ Erreur de recherche vectorielle:', err.message);
throw err;
}
}
/**
* Calcule un seuil adaptatif selon la longueur de la question
* @param {string} question - Question analysée
* @returns {number} Seuil de pertinence
*/
getAdaptiveThreshold(question) {
const wordCount = question.split(' ').length;
if (wordCount <= 3) return 0.75;
if (wordCount <= 6) return 0.80;
return 0.85;
}
}
export const vectorService = new VectorService();
5.2.3 Explications du code
- Méthode
search
async search(vector, limit = 3, scoreThreshold = 0.75) {
const results = await qdrant.search(COLLECTION_NAME, {
vector, // Le vecteur de la question
limit, // Nombre max de résultats
with_payload: true, // Récupérer les métadonnées
score_threshold: scoreThreshold // Seuil de pertinence
});
}
On demande à Qdrant de nous sortir les documents les plus proches de la question, mais pas trop loin (seuil de pertinence).
rag.js on utilise cette méthode comme ceci :const threshold = vectorService.getAdaptiveThreshold(question);
const searchResults = await vectorService.search(vector, 3, threshold);
Cela permet de limiter le nombre de résultats à 3 et d'appliquer un seuil de pertinence adaptatif en fonction de la longueur de la question getAdaptiveThreshold.
Parce que si la question est courte, on veut des résultats plus larges, mais si la question est longue, on veut des résultats plus précis.
Exemple : si on pose la question "Quel est le président de la France ?", on veut des résultats plus précis que si on pose la question "Quel est le président de la France et quel est son parti ?"
"RAG ?" → 0.65 // Question courte, tolérant
"embedding IA" → 0.80 // Technique, précis
"Comment utiliser..." → 0.75 // Longue, équilibré
"Bonjour" → 0.70 // Standard
Maintenant qu'on a nos services
RAGetvectoriel, on va créerl'API Expresspour exposer tout ça au monde extérieur !
6. Création de l'API Express
6.1. Comprendre le rôle de l'API Express
L'API Express est le point d'entrée de notre application. C'est elle qui va recevoir les questions de l'utilisateur, les envoyer au service RAG, et renvoyer la réponse.
/api/ask (Backend Express)6.2. Création du fichier chat.js
Dans le dossier routes/, créons un fichier chat.js :
import express from 'express';
import { ragService } from '../services/rag.js';
const router = express.Router();
/**
* Route POST /ask - Traite les questions utilisateur
*/
router.post('/ask', async (req, res) => {
try {
const { question } = req.body;
// Validation de base
if (!question || question.length > 1000) {
return res.status(400).json({
error: 'Question invalide ou trop longue'
});
}
// Traitement avec le service RAG
const result = await ragService.processQuestion(question);
res.json(result);
} catch (error) {
console.error('❌ Erreur dans /ask:', error.message);
res.status(500).json({
error: 'Erreur serveur: problème avec l\'API OpenAI'
});
}
});
export default router;
Ce code est relativement simple, on crée une route
POST /askqui va recevoir la question de l'utilisateur, la traiter avec le service RAG, et renvoyer la réponse.
6.3. Integration de la route dans dans le serveur principal app.js
A la racine du dossier backend/, on va créer un fichier app.js qui va servir de point d'entrée de notre application.
import express from 'express';
import path from 'path';
import { fileURLToPath } from 'url';
import bodyParser from 'body-parser';
import dotenv from 'dotenv';
// Services
import { vectorService } from './services/vector.js';
import chatRoutes from './routes/chat.js';
dotenv.config();
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
// Utiliser le PORT depuis .env avec fallback
const PORT = process.env.PORT || 3000;
// Vérification des variables d'environnement
if (!process.env.OPENAI_API_KEY) {
console.error('❌ OPENAI_API_KEY non défini dans .env');
process.exit(1);
}
const app = express();
// Vérification de la connexion Qdrant au démarrage
async function checkConnections() {
const isConnected = await vectorService.checkConnection();
if (!isConnected) {
process.exit(1);
}
}
checkConnections();
// Middlewares
app.use(bodyParser.json());
app.use(express.static(path.join(__dirname, 'public')));
app.set('view engine', 'pug');
app.set('views', path.join(__dirname, 'views'));
// Routes
app.get('/', (_, res) => {
res.render('index');
});
// Routes API
app.use('/', chatRoutes);
// Démarrage du serveur
app.listen(PORT, () => {
console.log(` App listening on http://localhost:${PORT}`);
});
Rien de plus basique, on importe les dépendances, on vérifie la connexion à Qdrant, on crée les middlewares, on ajoute les routes, et on démarre le serveur.
Tu a compris une fois notre
rag.jsest en place, c'est tout simple ! Ici on fais que d'appeler la méthodeprocessQuestiondu service RAG via notre routerchat.js.
7. Un peu de html/css/js pour finir notre assistant IA RAG
On va faire un truc très simple, l'idée c'est qu'un utilise arrive sur la page, il voit un input, il tape sa question, et il a la réponse juste au dessus.
Dans le dossier views/, créons un fichier index.pug :
doctype html
html(lang="fr")
head
title Chat IA avec RAG
link(rel="stylesheet", href="/styles.css")
meta(charset="utf-8")
meta(name="viewport", content="width=device-width, initial-scale=1")
body
.container
// Header
.header
h1 Assistant IA - RAG
p Recherche intelligente dans vos documents
// Chat Container
.chat-container
// Messages Area
#messages.messages-area
.welcome-message
i.fas.fa-robot
p Posez votre question sur l'IA, la gestion de projet ou la ville de Pabios
p.subtitle Vos documents seront analysés pour vous fournir une réponse précise
// Input Area
.input-area
.input-container
input#userInput(
type="text"
placeholder="Tapez votre question..."
autocomplete="off"
maxlength="500"
)
button#sendBtn.send-button
i#sendIcon.fas.fa-paper-plane
span#sendText Envoyer
// Scripts
script(src="/app.js")
Et c'est parti ! Vue que tu a pris le temps de lire ce fichier, tu a remarquer qu'il nous reste un styles.css et un app.js à créer. Je te laisse faire un effort de créativité pour le styles.css et pour le app.js je te propose les suivants :
Styles CSS:
Dans le dossier public/, créons un fichier styles.css :
/* Minimal CSS pour un design minimaliste */
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
font-family: sans-serif;
min-height: 100vh;
display: flex;
align-items: center;
justify-content: center;
padding: 1rem;
background: #f5f5f5;
}
.container {
width: 100%;
max-width: 64rem;
}
.header {
text-align: center;
margin-bottom: 2rem;
}
.header h1 {
font-size: 2rem;
font-weight: bold;
margin-bottom: 0.5rem;
}
.header p {
font-size: 1rem;
}
.chat-container {
background: #fff;
border-radius: 1rem;
border: 1px solid #eee;
box-shadow: 0 2px 8px rgba(0,0,0,0.05);
overflow: hidden;
}
.messages-area {
height: 20rem;
overflow-y: auto;
padding: 1rem;
display: flex;
flex-direction: column;
gap: 1rem;
}
.welcome-message {
text-align: center;
padding: 2rem;
}
.input-area {
padding: 1rem;
border-top: 1px solid #eee;
}
.input-container {
display: flex;
border-radius: 9999px;
overflow: hidden;
border: 1px solid #eee;
background: #fff;
}
input {
flex: 1;
padding: 0.5rem 1rem;
border: none;
outline: none;
background: transparent;
}
.send-button {
border: none;
padding: 0.5rem 1rem;
cursor: pointer;
background: #eee;
}
je te laisse y ajouter une bonne dause de css pour que ça soit plus joli, sans oublier la planète !
Maintenant pour finir, on va créer un fichier app.js dans le dossier public/ :
Car il faudrais qu'on puisse envoyer la question de l'utilisateur à notre API, et afficher la réponse.
/**
* Chat IA avec RAG - Frontend JavaScript
* Gestion de l'interface utilisateur et communication avec l'API
*/
// Variables globales
const input = document.getElementById('userInput');
const messages = document.getElementById('messages');
const sendBtn = document.getElementById('sendBtn');
const sendIcon = document.getElementById('sendIcon');
const sendText = document.getElementById('sendText');
/**
* Affiche l'indicateur de frappe de l'IA
*/
function showTypingIndicator() {
const typingHtml = `
<div id="typing-indicator" class="message ai-message">
<div class="message-content">
<i class="fas fa-robot"></i>
<span>IA réfléchit</span>
<div class="typing-indicator">
<div class="typing-dot"></div>
<div class="typing-dot"></div>
<div class="typing-dot"></div>
</div>
</div>
</div>
`;
messages.innerHTML += typingHtml;
scrollToBottom();
}
/**
* Supprime l'indicateur de frappe
*/
function removeTypingIndicator() {
const indicator = document.getElementById('typing-indicator');
if (indicator) {
indicator.remove();
}
}
/**
* Fait défiler la zone de messages vers le bas
*/
function scrollToBottom() {
messages.scrollTop = messages.scrollHeight;
}
/**
* Efface le message de bienvenue si présent
*/
function clearWelcomeMessage() {
const welcomeMessage = messages.querySelector('.welcome-message');
if (welcomeMessage) {
messages.innerHTML = '';
}
}
/**
* Ajoute un message utilisateur à l'interface
* @param {string} message - Le message de l'utilisateur
*/
function addUserMessage(message) {
const userMessageHtml = `
<div class="message user-message">
<div class="message-content">
<i class="fas fa-user"></i>
<div class="text">${message}</div>
</div>
</div>
`;
messages.innerHTML += userMessageHtml;
}
/**
* Ajoute une réponse IA à l'interface
* @param {Object} data - Données de la réponse (answer, sources, found)
*/
function addAIResponse(data) {
let html = `
<div class="message ai-message">
<div class="message-content">
<i class="fas fa-robot"></i>
<div class="text">${data.answer}</div>
</div>
`;
// Ajouter les sources si disponibles
if (data.sources && data.sources.length > 0) {
html += `
<div class="sources-box">
<div class="sources-header">
<i class="fas fa-book-open"></i>
<span>Sources consultées</span>
</div>
<ul class="sources-list">
`;
data.sources.forEach(source => {
html += `
<li class="source-item">
<i class="fas fa-file-alt"></i>
<span><em>${source.title}</em> — ${source.author}, ${source.date}</span>
<span class="score">${source.score}%</span>
</li>
`;
});
html += `</ul></div>`;
} else if (data.found === false) {
html += `
<div class="no-sources">
<i class="fas fa-exclamation-triangle"></i>
<span>Aucune source pertinente trouvée</span>
</div>
`;
}
html += '</div>';
messages.innerHTML += html;
}
/**
* Ajoute un message d'erreur à l'interface
* @param {string} errorMessage - Message d'erreur à afficher
*/
function addErrorMessage(errorMessage = "Erreur de communication avec le serveur") {
const errorHtml = `
<div class="message error-message">
<div class="message-content">
<i class="fas fa-exclamation-circle"></i>
<span>${errorMessage}</span>
</div>
</div>
`;
messages.innerHTML += errorHtml;
}
/**
* Active/désactive l'interface utilisateur
* @param {boolean} disabled - État d'activation
*/
function setUIState(disabled) {
input.disabled = disabled;
sendBtn.disabled = disabled;
if (disabled) {
sendIcon.className = 'fas fa-spinner fa-spin';
} else {
sendIcon.className = 'fas fa-paper-plane';
}
}
/**
* Envoie un message à l'API et traite la réponse
* @param {string} message - Message à envoyer
*/
async function sendMessageToAPI(message) {
try {
const response = await fetch('/ask', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({ question: message })
});
if (!response.ok) {
throw new Error(`Erreur HTTP: ${response.status}`);
}
const data = await response.json();
return data;
} catch (error) {
console.error('Erreur lors de l\'envoi du message:', error);
throw error;
}
}
/**
* Fonction principale pour envoyer un message
*/
async function sendMessage() {
const message = input.value.trim();
// Vérification du message
if (!message) {
return;
}
// Désactiver l'interface
setUIState(true);
// Effacer le message de bienvenue et ajouter le message utilisateur
clearWelcomeMessage();
addUserMessage(message);
// Vider l'input
input.value = '';
// Afficher l'indicateur de frappe
showTypingIndicator();
try {
// Envoyer le message à l'API
const data = await sendMessageToAPI(message);
// Supprimer l'indicateur de frappe
removeTypingIndicator();
// Ajouter la réponse IA
addAIResponse(data);
} catch (error) {
// Supprimer l'indicateur de frappe et afficher l'erreur
removeTypingIndicator();
addErrorMessage();
} finally {
// Réactiver l'interface
setUIState(false);
// Faire défiler vers le bas et remettre le focus
scrollToBottom();
input.focus();
}
}
/**
* Gestionnaire d'événement pour la touche Entrée
* @param {KeyboardEvent} event - Événement clavier
*/
function handleKeyPress(event) {
if (event.key === 'Enter' && !event.shiftKey) {
event.preventDefault();
sendMessage();
}
}
/**
* Initialisation de l'application
*/
function initializeApp() {
// Ajout des gestionnaires d'événements
input.addEventListener('keydown', handleKeyPress);
sendBtn.addEventListener('click', sendMessage);
// Focus automatique sur l'input
input.focus();
console.log('💬 Chat IA initialisé avec succès');
}
// Initialisation au chargement de la page
document.addEventListener('DOMContentLoaded', initializeApp);
Aussi simple que ça ! Maintenant on peut tester notre assistant IA RAG en local.
Tu a compris les etapes, on lance le conteneur Docker, on indexe les documents, et go sur http://localhost:3000.
A la racine du projet, à l'endroit ou se trouve le fichier compose.yaml.
docker compose up --build
Puis dans un autre terminal :
docker compose exec nodeapp npm run index
Et c'est tout ! Tu peux maintenant tester ton assistant IA RAG en local.
Et si tu veux voir le dashboard de Qdrant, tu peux aller sur http://localhost:6333/dashboard.
Pour rappel tu peux retrouver le code source de ce projet sur:
Github pobiosoft/pox-node-et-ia-rag
creer-son-premier-assistant-ia-rag-avec-nodejs8. Exercice: Expérimente le seuil adaptatif
Essaie de demander à l’IA: «Salut, tu connais macron?» Si elle te répond «non», tente: «Tu connais Emmanuel Macron?» Tu verras que la réponse change selon la formulation!
À toi de jouer: Va dans le fichier
rag.jset modifie la valeur duthresholddans la méthode correspondante. Observe comment le résultat varie selon la précision de ta question. Trouve le seuil qui fonctionne le mieux pour ton cas d’usage!
9. Fiche de révision : Les concepts clés
Question 1 : C'est quoi le RAG en une phrase ?
Le RAG (Retrieval-Augmented Generation) est une technique d’IA qui combine la recherche de documents et la génération de texte pour répondre précisément à une question en s’appuyant sur des sources fiables.
Question 2 : Pourquoi on transforme le texte en "vecteurs" ?
On transforme le texte en vecteurs pour permettre à l’IA de comparer le sens des phrases et retrouver les passages les plus pertinents dans la base de données.
Qdrant stocke les documents sous forme de vecteurs et permet de rechercher rapidement ceux qui ressemblent le plus à la question posée.
Question 4 : Comment notre assistant génère-t-il ses réponses ?
Il analyse la question, cherche les documents les plus proches dans Qdrant, puis utilise un modèle IA (LLM) pour formuler une réponse claire en citant ses sources.
Question 5 : Pourquoi notre assistant est-il fiable ?
Parce qu’il s’appuie sur des documents indexés et cite toujours ses sources, ce qui permet de vérifier l’origine des informations.
Question 6 : À quoi sert la notion de "temperature" dans la génération de texte ?
La "temperature", c’est le bouton qui règle si l’IA reste sage ou part en freestyle!
Plus c’est bas (genre 0.2), plus elle répond sérieux et précis.
Plus c’est haut (genre 0.8), plus elle invente et varie les réponses.
En gros: tu choisis entre IA studieuse ou IA créative.
Question 8 : Comment peut-on transformer un assistant RAG en agent IA autonome ?
Pour passer d’un assistant RAG à un agent IA autonome, c’est comme donner des bras et des jambes à ton assistant: il ne fait plus juste répondre, il peut agir tout seul !
On lui apprend à prendre des décisions, à lancer des actions (envoyer un mail, remplir un formulaire, piloter une API…), et à s’adapter selon la situation.
En gros, l’agent IA devient un vrai “collaborateur virtuel”: il comprend, il réfléchit, il fait des trucs pour toi, pas juste te donner des infos.